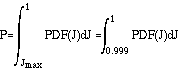
since expected value of Jmax is equal to 0.999. However, if by some knowledge about the problem we have learned that the maximum must lie in the region [0,0.5], then performing the same 1,000 samples in this reduced interval will change the probability to
If the PDF of J is uniform then a 50% reduction of the search space
produces a 100% improvement in the chance of finding the maximum. Of course,
there are many ways to reduce the search region using knowledge other than
simple partitioning. Some ways are more efficient than others. Properties
such as monotonicity, continuity, linearity, etc., can produce even more
significant reductions [Deng-Ho 1995].
Each time we sample from a search space, we of course gain information about
the distribution of the J(q)'s, i.e., we "learn".
This learned knowledge should be used to direct additional searches leading to
an iterative approach to sampling in the tradition of all successive
improvement methods such as gradient schemes and TABU search. The major
difference here is instead of iterate along a path or a sequence of points,
the iteration is done along a sequence of sampling representations. For each
representation we sample repeatedly to learn the global feature of the
distribution before changing the search representation. Ordinarily, this can
be very expensive leading to a huge number of required samples. It is here
that Ordinal Optimization makes a contribution rendering the evaluation of
J(q) much less costly by using very approximate
J(q)'s. If one representation yields a better looking observed
PDF, then we should concentrate and refine our search in that representation.
This is based on a gneralization of the following simple fact. If two numbers
A < B are observed under i.i.d. noise, the the observed PDF of A will
dominate that of B as illustrated below:
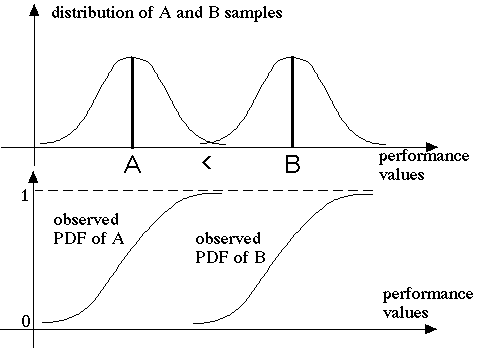
Now if instead A and B are random variables with distributions of their own,
we can still use the observed PDFs to guide our selection of promising
representations.
Using this approach of iterating along a sequence of possible representations,
we were able to